Randomness extractor
A randomness extractor, often simply called "an extractor," is a function which, when applied to a high-entropy source (such as radioactive decay, or thermal noise), generates a random output that is shorter, but uniformly distributed. In other words, outputting a completely random sample from a semi-random input.[1]
The goal of this process is to generate a truly random output stream, which could then be considered as being a true random number generator (TRNG).
A randomness extractor is an algorithm that converts a weakly random source and a truly random seed into a uniform distribution of random numbers. The weakly random source is usually longer than the output, and the truly random seed is short compared to the two. The only restriction for successful application of the extractor is that the high-entropy source is nondeterministic, in other words, there is no way in which the source can be fully controlled, calculated or predicted. An extractor is a certain kind of pseudorandom generator construction.
The goal in using extractors is to obtain a truly random sequence with a uniform distribution. When constructing an extractor, the aim is to get as long an output as possible when using as short as possible inputs; specifically the truly random seed's length is useful to minimize.
No single randomness extractor currently exists that has been proven to work when applied to any type of high-entropy source.
Contents |
Formal definition of extractors
When defining an extractor[2], we need a measurement of how well it extracts. In other words, we need to define the level of randomness it produces. For this is used min-entropy, which is a measurement of the amount of randomness in the worst case. The definition uses the worst case randomness of min-entropy and not the average case randomness described by Shannon-entropy.
Definition (Extractor): A (k, ε)-extractor is a function
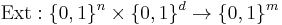
such that for every distribution X on {0, 1}n with 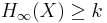 the distribution
the distribution 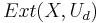 is ε-close to the uniform distribution on {0, 1}m.
is ε-close to the uniform distribution on {0, 1}m.
Futuremore, if 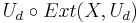 is ε-close to the uniform distribution on {0, 1}m+d, we call it as a strong (k, ε)-extractor.
is ε-close to the uniform distribution on {0, 1}m+d, we call it as a strong (k, ε)-extractor.
Now, the length of the weakly random input is required to be longer than the length of the output. The aim is to have a short as possible seed (low d), and an output that is as long as possible (high m), while keeping the min-entropy over a certain limit. In short we will have: n > m and we aim for d<< m.
Explicit extractors
By standard probabilistic method it can be shown that there exists a (k, ε)-extractor, i.e. that the construction is possible. It is however rarely enough to show the existence of an extractor. An explicit construction is needed:
Definition (Explicit Extractor): For functions k(n), ε(n), d(n), m(n) a family Ext = Extn of functions
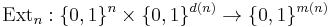
is an explicit (k, ε)-extractor if Ext(x, y) can be computed in polynomial time (in its input length) and for every n, Extn is a (k(n), ε(n))-extractor.
In words, this definition states that an extractor can be generated in polynomial time. It is worth to note that using the extractor is not a polynomial time operation, but rather a linear time operation on the input, plus any time needed to modify the input before using the extractor itself.
By the probabilistic method it can be shown that there exists a (k, ε)-extractor with seed length
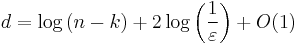
and output length
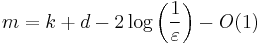 [3].
[3].
Dispersers
Another variant of the randomness extractor is the disperser.
Strong extractors
The two inputs taken by an extractor must be independent sources of randomness (the actual random source and a shorter seed). For an extractor to be a strong extractor it is required that concatenating the seed with the extractor's output yields a distribution that is close to uniform.
Definition (Strong Extractor): A 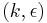 -strong extractor is a function
-strong extractor is a function
such that for every distribution 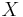 on
on 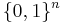 with the distribution (The two copies of
with the distribution (The two copies of 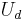 denote the same random variable) is
denote the same random variable) is 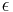 -close to the uniform distribution on
-close to the uniform distribution on 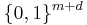 .
.
Randomness extractors in cryptography
This section is mainly based on [4]. Jesse Kamp and David Zuckerman examine deterministic extractors (extractors without an input seed), which is why the following section concerns extractors with only one input.
One of the most important aspects of cryptography is random key generation. It is often needed to derive secret and random keys using sources that are semi-secret. Using extractors, having a single short secret random key is sufficient to generate longer pseudo-random keys, which can be used for public key encryption. In other words, randomness extraction can be useful in the key derivation phase.
When using a strong extractor the output will appear be uniform, even to someone who sees the pseudo-random source (or the seed, but not both). In other words, the randomness, and thus the secrecy, of the output is intact even if the input source is compromised. The high level of randomness in the output along with the fact that every part of the output depends on the entire input, ensures that knowing part of the input will not reveal any part of the output. This is referred to as Exposure-Resilient cryptography wherein the desired extractor is used in a so called Exposure-Resilient Function (ERF).
The point of using Exposure-Resilient Functions is the practical application of these. When initializing a specific encryption application the parties often doesn't have any common and private knowledge. The initial exchange of data is difficult to keep completely secret, which is why Exposure-Resilient Functions are useful.
Definition (k-ERF): An adaptive k-ERF is a function 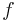 where, for a random input
where, for a random input 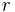 , when a computationally unbounded adversary
, when a computationally unbounded adversary  can adaptively read all of except for
can adaptively read all of except for  bits,
bits, ![|Pr[A^{r}(f(r)) = 1] - Pr[A^{r}(R) = 1]| \leq \epsilon(n)](/2012-wikipedia_en_all_nopic_01_2012/I/53be5263fa3a13dce79643551a55bf23.png) for some negligible function
for some negligible function 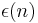 .
.
The goal is to construct adaptive ERF's when trying to extract output that is indistinguishable to uniform. Often a stronger condition is needed; that is that every output occurs with almost uniform probability. To solve this is used Almost-Perfect Resilient Functions (APRF):
Definition (k-APRF): A 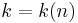 APRF is a function where, for any setting of
APRF is a function where, for any setting of 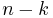 bits of the input to any fixed values, the probability vector
bits of the input to any fixed values, the probability vector 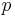 of the output
of the output 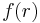 over the random choices for the remaining bits satisfies
over the random choices for the remaining bits satisfies 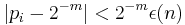 for all
for all  and for some negligible function .
and for some negligible function .
Kamp and Zuckerman[5] has a theorem stating that if a function is a k-APRF, then is also a k-ERF. More specific, any extractor for oblivious bit-fixing sources with small enough error is also an APRF and therefore also a k-ERF. A more specific extractor is expressed in this lemma:
Lemma: Any 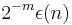 -extractor
-extractor 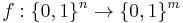 for the set of
for the set of 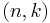 oblivious bit-fixing sources, where is negligible, is also a k-APRF.
oblivious bit-fixing sources, where is negligible, is also a k-APRF.
This lemma is proved by Kamp and Zuckerman[5]. The lemma is proved by examining the distance from uniform of the output, which in a -extractor obviously is at most, which satisfies the condition of the APRF.
The lemma leads to the following theorem, stating that there in fact exists a k-APRF function as described: Theorem (existence): For any positive constant 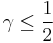 , there exists an explicit k-APRF , computable in a linear number of arithmetic operations on
, there exists an explicit k-APRF , computable in a linear number of arithmetic operations on 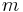 -bit strings, with
-bit strings, with 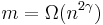 and
and 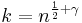 .
.
In the proof of this theorem, we need a definition of a negligible function. Negligibility is defined as a function being negligible if 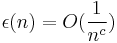 for all constants
for all constants 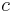 .
.
Proof: Consider the following -extractor: The function is an extractor for the set of 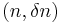 oblivious bit-fixing source: . has
oblivious bit-fixing source: . has 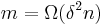 ,
, 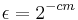 and
and 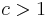 .
.
The proof of this extractor's existence with 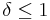 , as well as the fact that it is computable in linear computing time on the length of can be found in the paper by Jesse Kamp and David Zuckerman (p. 1240).
, as well as the fact that it is computable in linear computing time on the length of can be found in the paper by Jesse Kamp and David Zuckerman (p. 1240).
That this extractor fulfills the criteria of the lemma is trivially true as is a negligible function.
The size of is: 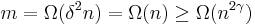 Since we know then the lower bound on is dominated by
Since we know then the lower bound on is dominated by  . In the last step we use the fact that which means that the power of is at most
. In the last step we use the fact that which means that the power of is at most 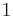 . And since is a positive integer we know that
. And since is a positive integer we know that 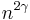 is at most .
is at most .
is calculated by using the definition of the extractor, where we know:
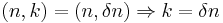
and by using the value of we have:
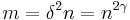
Using this value of we account for the worst case, where is on its lower bound. Now by algebraic calculations we get:
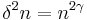
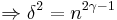
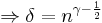
Which inserted in the value of gives
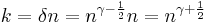 ,
,
which proves that there exists an explicit k-APRF extractor with the given properties. 
Examples
Von Neumann extractor
Perhaps the earliest example is due to John von Neumann. His extractor took successive pairs of consecutive bits (non-overlapping) from the input stream. If the two bits matched, no output was generated. If the bits differed, the value of the first bit was output. The Von Neumann extractor can be shown to produce a uniform output even if the distribution of input bits is not uniform so long as each bit has the same probability of being one and there is no correlation between successive bits.[6]
Thus, it takes as input a Bernoulli sequence with p not necessarily equal to 1/2, and outputs a Bernoulli sequence with 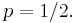 More generally, it applies to any exchangeable sequence – it only relies on the fact that for any pair, 01 and 10 are equally likely: for independent trials, these have probabilities
More generally, it applies to any exchangeable sequence – it only relies on the fact that for any pair, 01 and 10 are equally likely: for independent trials, these have probabilities 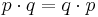 , while for an exchangeable sequence the probability may be more complicated, but both are equally likely.
, while for an exchangeable sequence the probability may be more complicated, but both are equally likely.
Cryptographic hash
Another approach is to fill a buffer with bits from the input stream and then apply a cryptographic hash to the buffer and use its output. This approach generally depends on assumed properties of the hash function.
Applications
Randomness extractors are used widely in cryptographic applications, whereby a cryptographic hash function is applied to a high-entropy, but non-uniform source, such as disk drive timing information or keyboard delays, to yield a uniformly random result.
Randomness extractors have played a part in recent developments in quantum cryptography, where photons are used by the randomness extractor to generate secure random bits.[1]
Randomness extraction is also used in some branches of computational complexity theory.
Random extraction is also used to convert data to a simple random sample, which is normally distributed, and independent, which is desired by statistics.
References
- ^ http://portal.acm.org/citation.cfm?coll=GUIDE&dl=GUIDE&id=796582
- ^ Ronen Shaltiel. Recent developments in explicit construction of extractors. pp. 5–8.
- ^ Ronen Shaltiel. Recent developments in explicit construction of extractors. P. 5.
- ^ Jesse Kamp and David Zuckerman. Deterministic Extractors for Bit-Fixing Sources and Exposure-Resilient Cryptography. P. 1241-1242.
- ^ a b Jesse Kamp and David Zuckerman. Deterministic Extractors for Bit-Fixing Sources and Exposure-Resilient Cryptography. P. 1242.
- ^ John von Neumann. Various techniques used in connection with random digits. Applied Math Series, 12:36–38, 1951.
- Extractors and Pseudorandom Generators, Luca Trevisan
- Recent developments in explicit constructions of extractors, Ronen Shaltiel
- Randomness Extraction and Key Derivation Using the CBC, Cascade and HMAC Modes, Yevgeniy Dodis et al.
- Key Derivation and Randomness Extraction, Olivier Chevassut et al.
- Deterministic Extractors for Bit-Fixing Sources and Exposure-Resilient Cryptography, Jesse Kamp and David Zuckerman
- Tossing a Biased Coin (and the optimality of advanced multi-level strategy) (lecture notes), Michael Mitzenmacher